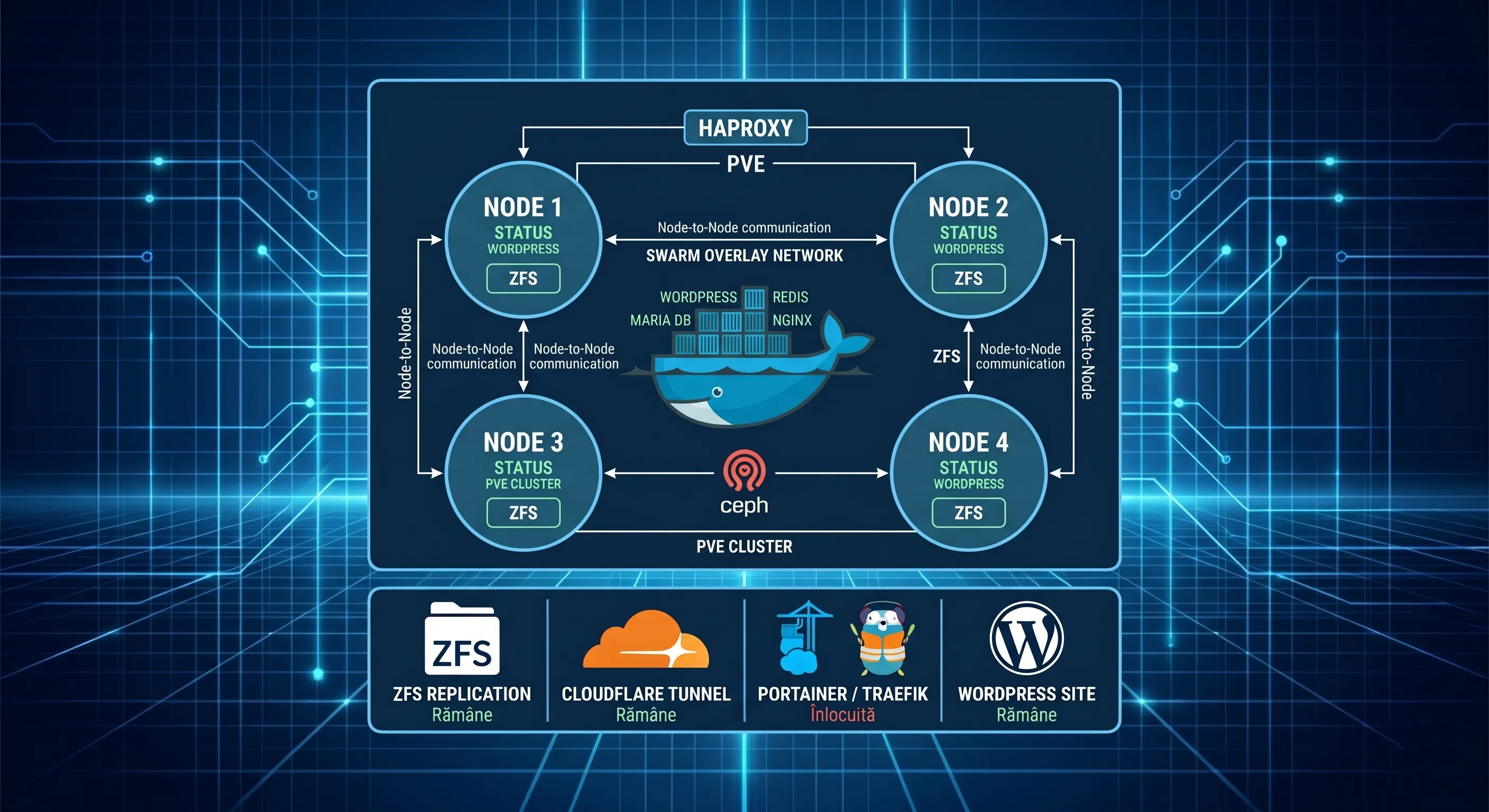
Această serie te învață cum să treci de la un hosting clasic la o arhitectură avansată, explicând pas cu pas cum să implementezi propriul cluster Docker Swarm pentru a rula un site WordPress complet scalabil.
🔹Episodul 0: Trecerea la nivelul Enterprise și Arhitectura Proiectului
„Am construit împreună un tanc (Proxmox HA). Acum, în loc să punem în el un motor clasic, îi punem un motor de rachetă: Docker Swarm.”
Bun venit la un nou capitol al călătoriei noastre. Lăsăm în urmă panourile de control clasice și construim propria noastră infrastructură de containere.
Ce păstrăm din seria „De la zero la un site complet” (Fundația obligatorie):
Pentru ca acest nou proiect să funcționeze, ne vom baza pe infrastructura solidă pe care am construit-o în seria precedentă ( https://tech.renuka.ro/pt-portfolio/de-la-zero-la-un-site-complet/). Dacă nu ai parcurs acei pași, îți recomand să revizuiești următoarele capitole:
- Episodul 0: Fundația. Cluster Proxmox și High Availability (HA)
- Episodul 1: Alegerea și cumpărarea unui domeniu ieftin – Namecheap –
- Episodul 2: Configurarea domeniului în Cloudflare + SSL gratuit
- Episodul 3: Arhitectura Invizibilă. Cloudflare Tunnel și Replicarea ZFS
Structura Noului Proiect (Cele 6 Episoade Indestructibile):
În acest proiect vom construi pas cu pas o arhitectură Enterprise, distribuită logic pe următoarele episoade:
- Episodul 0: Fundația Software. Instalarea Docker Swarm (Sistemul de operare al clusterului).
- Episodul 1: Centrul de Comandă. Instalarea Portainer (Managementul vizual al clusterului).
- Episodul 2: Conectarea la Internet. Reconfigurarea Cloudflare Tunnel (Accesul și Rutarea directă).
- Episodul 3: Site-ul propriu-zis. Lansarea WordPress (Motorul) și MariaDB (Seiful).
- Episodul 4: Uneltele de Mentenanță. Adăugarea FileBrowser și phpMyAdmin (Intervenția).
- Episodul 5: Monitorizare și Supraviețuire. Grafana (Sănătatea) și Duplicati (Backup-ul extern).
🔹Preambul: Fundația Software. Instalarea Docker Engine și Inițializarea Swarm-ului
Aplicațiile noastre au nevoie de un „pământ” stabil pe care să fie construite. Acel pământ este motorul Docker, pe care îl vom instala pe două noduri strategice: mașina ta fizică cu Ubuntu (Managerul – .111) și mașina virtuală din Proxmox (Worker-ul – .112), care beneficiază de replicarea ZFS între pve1 și pve2 pentru disponibilitate maximă.
⚠️ NOTĂ CRUCIALĂ: Curățenia mediului. Nu instalați Docker peste vechiul proiect (CyberPanel) pentru a evita conflictele. Vom folosi un mediu complet proaspăt.
a. Crearea și Pregătirea „Casei” pentru Docker
În Proxmox, am creat VM-ul cu ID-ul 201, numit docker-worker-01 (Ubuntu Server, 4GB RAM, 2 Core-uri CPU).
Regula de aur (Replicarea ZFS): Imediat după creare, am setat replicarea la fiecare minut către nodul secundar. Pentru a finaliza pregătirea sistemului de operare, executăm următoarele comenzi pe noul server:
# Actualizarea sistemului și instalarea agentului de comunicare cu Proxmox
sudo apt update && sudo apt upgrade -y
sudo apt install qemu-guest-agent -y
sudo systemctl enable --now qemu-guest-agent
# Sincronizarea fusului orar (București)
sudo timedatectl set-timezone Europe/Bucharestb. Instalarea Docker Engine
Odată ce sistemele sunt pregătite, trecem la instalarea motorului Docker. Această procedură se execută atât pe laptopul Manager (.111), cât și pe noul VM Worker (.112):
# Descărcarea și rularea scriptului oficial Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
# Aplicarea permisiunilor pentru utilizatorul curent
sudo usermod -aG docker $USER
newgrp dockerc. Crearea Clusterului (Marea Unire Docker Swarm)
Transformăm cele două entități într-un singur organism. Primul pas se face pe Manager (.111):
# Inițializarea clusterului Swarm
docker swarm init --advertise-addr 192.168.1.111Copiați comanda de tip docker swarm join --token... generată de manager și rulați-o în consola serverului docker-worker-01 (.112).
d. Verificarea Clusterului
Întoarce-te pe laptop (Manager) și verifică dacă „muncitorul” s-a alăturat cu succes:
docker node lsDacă ambele noduri apar cu statusul Ready, felicitări! Ai un cluster Docker Swarm funcțional.
🔹Episod Intermediar (0.5): Curățenia și Uniformizarea Numelor
Înainte de a trece la configurarea accesului extern, facem o scurtă pauză pentru a ne asigura că infrastructura noastră respectă standardele Enterprise. În pașii anteriori, am instalat sistemul pe un user generic (renuka), dar într-un cluster profesionist, dorim ca identitatea fiecărei mașini să reflecte rolul ei.
De ce facem această schimbare?
- Claritate: Este mult mai ușor să identifici un nod ca fiind
worker-01decât după numele celui care l-a instalat. - Scalabilitate: Pregătim terenul pentru momentele când vom adăuga
worker-02,worker-03, etc.
Comenzile de Uniformizare (Executate pe Worker – .112)
Vom schimba “numele de buletin” al serverului (Hostname) pentru a se potrivi cu numele din Proxmox. Rulează aceste comenzi în terminalul nodului secundar:
# 1. Schimbăm numele mașinii în sistem
sudo hostnamectl set-hostname docker-worker-01
# 2. Actualizăm fișierul de rețea intern (înlocuim vechiul nume "renuka" cu cel nou)
sudo sed -i 's/renuka/docker-worker-01/g' /etc/hosts
# 3. Aplicăm schimbarea (necesită un logout/login sau restart)
sudo rebootCe s-a schimbat? După restart, prompt-ul tău nu mai este renuka@renuka, ci renuka@docker-worker-01. Clusterul Docker Swarm va prelua automat noul nume în listă, oferindu-ți o viziune clară asupra resurselor tale.
Gata! Acum avem o fundație curată și suntem gata să deschidem porțile către Internet în Episodul 2.
🔹Episodul 1: Centrul de Comandă. Instalarea Portainer
Clusterul nostru Docker Swarm este acum viu, dar momentan este „orb”. Pentru a gestiona eficient resursele fără a tasta comenzi interminabile în terminal, avem nevoie de un punct central de control:
- Portainer (Centrul de Comandă): Interfața grafică de unde vom administra containerele, volumele și rețelele de pe toate nodurile simultan.
a. Construirea “Autostrăzii”: Rețeaua Overlay
Înainte de aplicații, creăm o rețea de tip overlay. Aceasta permite containerelor aflate pe servere diferite (Laptop și Proxmox) să comunice securizat, ca și cum ar fi în același switch. Rulează pe Manager (.111):
# Creăm rețeaua publică principală a clusterului
docker network create --driver=overlay swarm-publicb. Instalarea Portainer Stack
În Swarm, instalăm Portainer ca un Stack. Aceasta va lansa automat un “Agent” pe fiecare nod disponibil pentru a colecta datele tehnice. Rulăm pe Manager:
# Descărcăm configurația oficială Portainer pentru Swarm
curl -L https://downloads.portainer.io/ce2-19/portainer-agent-stack.yml -o portainer-agent-stack.yml
# Lansăm stack-ul în cluster
docker stack deploy -c portainer-agent-stack.yml portainer⚠️ Securitate: Ai 5 minute să configurezi user-ul de admin la adresa https://192.168.1.111:9443. Dacă expiră, resetează serviciul cu: docker service update --force portainer_portainer.
c. Finalizarea interfeței și curățarea mediilor
După logare, dacă observi un mediu numit “primary” cu eroare, este recomandat să îl ștergi din Settings -> Environments. Mediul funcțional va fi cel creat prin conexiunea la agenți, care îți arată întreaga putere a clusterului tău sub un singur nume: Swarm-Cluster.
Clusterul este acum complet vizibil! Ești pregătit să lansezi aplicații cu un simplu click.
🔹Under the Hood: The Docker Swarm DNS Magic
La prima pornire, Portainer te va întreba cum dorești să te conectezi la mediul Docker. Pentru un cluster Swarm, secretul stă în utilizarea DNS-ului intern al Docker-ului.
În ecranul “Environment Wizard”, urmează acești pași critici:
- Alege tipul de mediu: Docker Swarm.
- Selectează metoda de conectare: Agent.
- La câmpul Environment address, introdu adresa:
tasks.agent:9001
De ce folosim “tasks.agent” în loc de un IP?
- Service Discovery: În Docker Swarm,
tasks.nume_serviciueste o intrare DNS specială care returnează IP-urile tuturor containerelor din acel serviciu. - Scalabilitate Automată: Când vei adăuga noduri noi în viitor, Swarm le va atribui automat un IP intern și le va înregistra sub acest nume. Portainer va “vedea” noile servere instantaneu, fără ca tu să mai modifici vreodată configurația.
- Reziliență: Dacă un nod pică, DNS-ul intern scoate acel IP din listă, iar Portainer continuă să comunice cu restul clusterului fără întrerupere.
🔹Episodul 2: Conectarea la Internet. Reconfigurarea Cloudflare Tunnel
În acest capitol transformăm clusterul nostru dintr-un laborator izolat într-o infrastructură vizibilă global. Vom folosi Cloudflare Tunnel pentru a ruta traficul securizat către serviciile noastre, fără a deschide niciun port în router.
De ce instalăm Tunelul pe Worker-ul din Proxmox?
Deși avem două noduri, am ales să rulăm containerul cloudflared pe mașina virtuală din Proxmox (Worker – .112). Motivul este simplu: Supraviețuirea. Datorită replicării ZFS și a sistemului High Availability (HA) din Proxmox, dacă serverul fizic pe care rulează Worker-ul are o problemă, acesta va fi mutat și repornit automat pe nodul secundar, restabilind conexiunea la internet fără intervenția noastră.
a. Pregătirea în Cloudflare Zero Trust
- Accesăm panoul Cloudflare Zero Trust -> Networks -> Tunnels.
- Creăm un tunel nou numit
swarm-enterprise-tunnel. - Selectăm metoda de instalare Docker și copiem doar Token-ul (șirul lung de caractere după
--token).
b. Lansarea Tunelului în Swarm (Executat pe Manager – .111)
Nu vom rula un simplu container, ci un Docker Service. Acesta va fi atașat rețelei swarm-public, devenind “ușa de intrare” pentru toate aplicațiile viitoare. Înlocuiește [TOKEN-UL_TAU] cu cel copiat anterior:
# Crearea serviciului Cloudflare Tunnel în cluster
docker service create \
--name cloudflare-tunnel \
--network swarm-public \
--constraint 'node.role == worker' \
--env TUNNEL_TOKEN=[TOKEN-UL_TAU] \
cloudflare/cloudflared:latest \
tunnel --no-autoupdate runc. Rutarea Serviciilor (Strategia “Port 9000”)
Odată ce tunelul apare cu statusul HEALTHY în Cloudflare, putem mapa subdomeniile noastre direct către containerele din rețea. Deoarece folosim o interfață simplificată (unde setările avansate de TLS nu sunt expuse), vom folosi calea cea mai stabilă:
- Public Hostname:
admin.renuka.site - Service Type:
HTTP - URL:
portainer_portainer:9000
💡 Notă Enterprise și Depanare: În demonstrația video am folosit IP-ul local (192.168.1.111:9000) pentru o conectare rapidă și universală. Totuși, pentru o arhitectură Enterprise, folosim numele serviciului. Reține două detalii critice pentru ca acest lucru să funcționeze:
- Numele de Stack: În Docker Swarm, serviciile primesc prefixul stack-ului din care fac parte. Astfel, adresa corectă este
portainer_portainer, nu doarportainer. - Rețeaua Comună: Pentru ca tunelul să “vadă” Portainer-ul, trebuie să adăugați manual serviciul portainer_portainer în rețeaua swarm-public din interfața Portainer (Services -> portainer_portainer -> Network -> Add to swarm-public).
Verificarea Rezilienței: Scenarii de Eșec și Plase de Siguranță
Arhitectura noastră Enterprise este construită să supraviețuiască atunci când inevitabilul se produce. Într-un mediu real, Worker-ul nostru (.112) poate deveni indisponibil din mai multe motive, declanșând diferite straturi de protecție:
- 1. Eșec Hardware (Cade „Tancul”): Serverul fizic principal (pve1) rămâne fără curent electric sau suferă o defecțiune fizică. Aici, efortul din Seria: “De la 0 la un site complet” ( Episodul 0: Fundația. Cluster Proxmox și High Availability (HA) ) dă roade: Proxmox intervine și mută mașina virtuală pe nodul de rezervă (pve2) folosind Replicarea ZFS, repornind Worker-ul și reconectând tunelul în aproximativ un minut.
- 2. Eșec la nivel de Sistem de Operare: Mașina virtuală rămâne fără memorie RAM (Out of Memory), stocarea se umple 100%, sau Ubuntu suferă un blocaj critic (Kernel Panic).
- 3. Eșec de Rețea sau Serviciu: Cablul de rețea este deconectat accidental, un firewall blochează brusc comunicarea, sau serviciul intern Docker Engine se oprește.
În cazurile 2 și 3, sau pe durata transferului hardware de la punctul 1, intervine planificatorul software al clusterului (Managerul .111). Deoarece am impus regula --constraint 'node.role == worker', Managerul știe că nu are voie să preia el sarcina. Cât timp Worker-ul este picat, Swarm-ul nu distruge serviciile, ci le trece într-o Coadă de Așteptare (Pending). Imediat ce Worker-ul raportează că a revenit online, Managerul injectează instantaneu serviciile înapoi în el.
Pentru a înțelege exact cum gândește „creierul” clusterului și cum ia decizii de alocare a containerelor pe baza acestor evenimente, am construit simulatorul interactiv de mai jos. Oprește Worker-ul pentru a simula o pană și lansează servicii pentru a vedea cum acționează Coada de Așteptare:
Ghid de Configurare: Traseul Enterprise în Simulator
Pentru a înțelege exact cum funcționează “plasa de siguranță” pe care am construit-o în acest episod, configurează simulatorul de mai sus urmând acești pași. Acest traseu reflectă realitatea tehnică a clusterului nostru:
Pasul 1: Setează Constrângerea
Alege din meniul drop-down: 🟢 Doar Worker (node.role==worker). Aceasta este setarea critică din comanda noastră de lansare. Îi spui Managerului că site-ul WordPress are nevoie de “masa” lui (datele de pe discul ZFS al Worker-ului).
Pasul 2: Simulează Pana Hardware
Oprește Worker-ul (comută pe OPRIT). Acesta este momentul în care serverul fizic PVE1 a picat. Vei observa că toate task-urile active dispar de pe Worker.
Pasul 3: Lansează un Task Nou
Apasă butonul ▶ Lansează Task. Vei vedea cum task-ul “zboară” direct în Coadă de Așteptare (Pending). Managerul știe că nu are voie să îl ruleze pe el însuși și îl păstrează special pentru când Worker-ul va fi mutat de Proxmox.
Pasul 4: Reconcilierea (Revenirea la viață)
Pornește Worker-ul (comută pe PORNIT). Aceasta simulează momentul în care Proxmox HA a terminat de mutat și pornit VM-ul pe PVE2. Observă cum task-ul din Pending “sare” instantaneu pe Worker. Site-ul tău este din nou online, automat!
De ce este acesta traseul corect? Deși am putea lăsa Swarm-ul să mute task-ul pe Manager (varianta Spread), site-ul ar da eroare pentru că Managerul (.111) nu are acces fizic la fișierele tale stocate pe discul virtual replicat. Prin acest traseu, forțăm software-ul (Docker) să aștepte după hardware (Proxmox), garantând că aplicația pornește doar acolo unde are și datele necesare lângă ea.
Acesta este secretul unei arhitecturi Enterprise: Răbdarea inteligentă a sistemului în fața dezastrului.
🔹Episodul 2.5 (Intermezzo): Matrix-ul Clusterului. Vizualizarea Live cu Swarm Visualizer
„Până acum am lucrat în întuneric, trimițând comenzi într-un ecran negru. Este timpul să aprindem lumina și să vedem cum arată cu adevărat ‘creierul’ și ‘mușchii’ infrastructurii noastre.”
Docker Swarm este o entitate abstractă. Știm că există, știm că mută containerele de pe un nod pe altul, dar este greu de vizualizat fără unelte potrivite. În acest scurt intermezzo, instalăm un utilitar care transformă liniile de cod în grafică live.
De ce avem nevoie de Swarm Visualizer?
Deși Portainer (Episodul 1) ne oferă control total, Swarm Visualizer ne oferă o perspectivă spațială. Este unealta perfectă pentru a înțelege:
- Distribuția Task-urilor: Vezi exact pe ce nod fizic a „aterizat” fiecare container.
- Starea de Sănătate: Dacă un nod pică, vei vedea în timp real cum cutiuțele (containerele) dispar de pe el și sunt recreate automat pe nodurile rămase active.
- Simularea Orchestrării: Este cea mai bună metodă didactică de a vedea cum funcționează „roiul” de containere.
Instalarea Vizualizatorului (Comanda de activare)
Această aplicație trebuie să ruleze obligatoriu pe Manager Node (.111), deoarece are nevoie de acces direct la fișierul de comunicare al Docker-ului (docker.sock) pentru a „citi” starea clusterului. Rulează următoarea comandă în terminal:
# Crearea serviciului de vizualizare pe portul 8080
docker service create \
--name=swarm-visualizer \
--publish=8080:8080/tcp \
--constraint=node.role==manager \
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
dockersamples/visualizerCum accesăm „Tabloul de Bord”?
Odată ce serviciul a fost creat, nu trebuie să mai facem nicio configurare în Cloudflare (fiind un utilitar intern de diagnoză). Pur și simplu deschide un browser din rețeaua ta locală și accesează:
http://192.168.1.111:8080<Ce vei vedea? Vei vedea o coloană pentru fiecare nod activ. În interiorul coloanelor, vei găsi containerele tale actuale: portainer, cloudflare-tunnel și, bineînțeles, noul swarm-visualizer.
Sfat Enterprise: În momentul în care vei porni nodul Worker (.112) în episoadele următoare, vei vedea cum Visualizer-ul adaugă automat o nouă coloană și cum task-urile încep să se balanseze între cele două mașini.
🔹Episodul 3: Site-ul propriu-zis. Lansarea WordPress și MariaDB
În acest capitol instalăm „inima” clusterului nostru. Nu vom lansa simple containere, ci un Stack Enterprise complet. Această arhitectură asigură că baza de date este complet izolată de internet, iar fișierele site-ului sunt protejate prin replicarea ZFS pe care am configurat-o în Proxmox.
1. Pregătirea stocării pe Worker (.112)
Pentru ca site-ul să nu piardă date în cazul unei mutări automate a Worker-ului între nodurile Proxmox, mapăm volumele într-o locație replicată. Executăm următoarele comenzi pe nodul Worker:
# Crearea structurii de foldere pe stocarea replicată
sudo mkdir -p /mnt/data/wordpress/html
sudo mkdir -p /mnt/data/wordpress/db
sudo chmod -R 777 /mnt/data/wordpress/2. Lansarea Stack-ului în Portainer
În Portainer, mergem la Stacks -> Add Stack și definim întreaga infrastructură a site-ului. Folosim DNS-ul intern Docker pentru ca WordPress să vorbească cu baza de date fără a expune porturi în exterior:
version: '3.8'
services:
db:
image: mariadb:latest
restart: always
volumes:
- /mnt/data/wordpress/db:/var/lib/mysql
environment:
MARIADB_ROOT_PASSWORD: ParolaTaSecreta
MARIADB_DATABASE: wordpress
MARIADB_USER: wp_user
MARIADB_PASSWORD: ParolaWPUser
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
wordpress:
image: wordpress:latest
depends_on:
- db
volumes:
- /mnt/data/wordpress/html:/var/www/html
environment:
WORDPRESS_DB_HOST: wordpress_db
WORDPRESS_DB_USER: wp_user
WORDPRESS_DB_PASSWORD: ParolaWPUser
WORDPRESS_DB_NAME: wordpress
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
networks:
swarm-public:
external: true3. Configurarea Accesului Extern (Cloudflare Tunnel)
Acum vine partea cea mai interesantă: conectarea WordPress-ului la internet. În panoul Cloudflare Zero Trust, adăugăm noua rută:
- Public Hostname:
www.renuka.site - Service Type:
HTTP - URL:
wordpress_wordpress:80(Respectăm regula: nume-stack_nume-serviciu)
Un mare avantaj al acestei metode este că NU mai trebuie să adăugați record-uri A sau CNAME în panoul DNS clasic Cloudflare. Atunci când salvați setările în Tunel, Cloudflare creează automat ruta DNS necesară. Este mult mai sigur, deoarece IP-ul de acasă rămâne complet ascuns.
De ce este aceasta o soluție Enterprise?
Această configurație transformă un simplu site WordPress într-o fortăreață:
- Baza de date este „Invizibilă”: MariaDB nu are porturi deschise și nu este configurată în tunel. Doar WordPress poate comunica cu ea, prin rețeaua internă.
- Supraviețuire Automată: Dacă Worker-ul pică, Proxmox îl mută pe PVE2. Tunelul se reconectează, WordPress găsește baza de date la același nume (
wordpress_db), iar fișierele sunt acolo datorită replicării ZFS. - Eficiență: Tot traficul este criptat prin tunel, fără a fi nevoie să gestionăm manual certificate SSL pe server.
Deoarece am trecut de la LiteSpeed la o arhitectură Docker, avem nevoie de un motor de cache care să lucreze în RAM. Pentru a activa acest “turbo”, adăugați următoarele linii în fișierul YAML de mai sus, imediat sub serviciul
wordpress (dar înainte de secțiunea networks): redis:
image: redis:latest
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]După ce actualizați Stack-ul, instalați în WordPress plugin-ul “Redis Object Cache” și activați-l. Aceasta va reduce drastic încărcarea bazei de date, oferind o viteză superioară celei pe care o aveați în panourile de control clasice.
🔹Episodul 4: Uneltele de Mentenanță. FileBrowser și phpMyAdmin
Odată ce WordPress-ul este online și funcțional, avem nevoie de o modalitate „civilizată” de a interveni sub capotă. Într-o arhitectură Enterprise, nu ne dorim să intrăm prin terminal (SSH) de fiecare dată când trebuie să modificăm o temă, un fișier .htaccess sau o valoare din baza de date.
Prin urmare, vom instala două unelte esențiale care vor acționa ca niște „uși de serviciu” către infrastructura noastră: FileBrowser (managerul de fișiere web) și phpMyAdmin (interfața pentru MariaDB).
1. Pregătirea stocării pe Worker (.112)
La fel ca la site-ul principal, aceste unelte au nevoie de spațiu fizic pe disc pentru a-și salva propriile setări și baze de date interne. Pentru a nu pierde aceste date la un eventual restart, creăm foldere dedicate pe stocarea replicată ZFS. Un detaliu critic aici este crearea manuală a fișierului bazei de date pentru FileBrowser înainte de lansare.
Ne conectăm pe nodul Worker (.112) și executăm:
# Crearea folderelor principale de configurare pentru mentenanță
sudo mkdir -p /mnt/data/maintenance/filebrowser
sudo mkdir -p /mnt/data/maintenance/pma
# Crearea fișierului gol pentru baza de date a FileBrowser (Pas critic!)
sudo touch /mnt/data/maintenance/filebrowser/filebrowser.db
# Aplicăm permisiunile 777 pentru a permite Docker-ului să scrie datele
sudo chmod -R 777 /mnt/data/maintenance/2. Lansarea Stack-ului de Mentenanță
O regulă de bază în DevOps este izolarea. Nu vom adăuga aceste unelte peste aplicația principală (WordPress). Vom crea un Stack nou în Portainer, numit maintenance. De ce? Pentru că dacă dorim să eliberăm resurse (RAM) pe viitor, putem opri complet acest stack fără ca site-ul public să fie afectat vreo secundă.
Navigăm în Portainer la Stacks -> Add Stack și introducem următorul cod:
version: '3.8'
services:
filebrowser:
image: filebrowser/filebrowser:latest
user: 0:0 # Rulăm cu drepturi de root pentru a putea edita fișierele create de WordPress
volumes:
- /mnt/data/wordpress/html:/srv
- /mnt/data/maintenance/filebrowser/filebrowser.db:/database.db
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
phpmyadmin:
image: phpmyadmin:latest
environment:
- PMA_HOST=wordpress_db # Esențial: Așa apelăm baza de date din celălalt stack!
- PMA_PORT=3306
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
networks:
swarm-public:
external: true3. Configurarea în Cloudflare Tunnel
În acest moment, containerele noastre funcționează, dar sunt izolate în rețeaua internă. Pentru a le putea accesa din browserul nostru, ne folosim de tunelul existent pe care l-am creat în Episoadele trecute.
Mergem în panoul Cloudflare Zero Trust -> Tunnels, configurăm tunelul nostru și adăugăm două rute noi (Public Hostnames):
- Manager Fișiere:
files.renuka.site➡️ direcționat cătrehttp://maintenance_filebrowser:80 - Bază de Date:
db.renuka.site➡️ direcționat cătrehttp://maintenance_phpmyadmin:80
- Manager Fișiere:
Nu trebuie să adăugați nimic manual în DNS! Cloudflare creează rutele automat, păstrând în continuare IP-ul de acasă complet ascuns.
4. Ghid de Autentificare: Cu ce date ne logăm?
Aici intervine frumusețea sistemelor interconectate. Dacă încercați să accesați noile adrese, veți fi întâmpinați de ecrane de login.
A. În FileBrowser (files.renuka.site):
- Încercați să vă logați cu datele implicite:
adminla user șiadminla parolă. - Schimbați parola imediat din interfață! Odată logați, veți avea acces vizual la tot folderul
htmlal WordPress-ului.
- Încercați să vă logați cu datele implicite:
Din motive de securitate, unele versiuni recente de FileBrowser anulează parola “admin” și generează una aleatorie la prima pornire. Dacă nu vă puteți loga, mergeți în Portainer la secțiunea Containers, dați click pe iconița Logs (foaia de hârtie) din dreptul containerului
maintenance_filebrowser, iar acolo veți găsi parola unică generată de sistem. Folosiți-o pentru prima conectare!B. În phpMyAdmin (db.renuka.site):
- Aici NU aveți nevoie de un cont nou creat! phpMyAdmin folosește identitatea bazei de date.
- Vă veți loga cu datele pe care le-ați definit în fișierul YAML din Episodul 3:
- Pentru acces complet: User
root+ Parola de laMARIADB_ROOT_PASSWORD. - Pentru acces limitat: User
wp_user+ Parola de laMARIADB_PASSWORD.
- Pentru acces complet: User
Imediat ce apăsați butonul „Deploy” în Portainer, deschideți tab-ul cu Swarm Visualizer (aplicația pe care am instalat-o în Episodul 2.5). Veți vedea în timp real cum „creierul” Docker Swarm trimite noile containere exact pe nodul Worker (.112), chiar lângă WordPress. Este confirmarea vizuală absolută că ambele aplicații au acces fizic la aceleași discuri ZFS.
Deși aceste „uși” sunt acum la un click distanță, locația serverului tău fizic rămâne o enigmă pe internet, iar intrarea este condiționată de chei solide.
Stay Free! Stay Hidden!
🔹Episodul 5: Monitorizare și Supraviețuire. Grafana (Sănătatea) și Duplicati (Backup-ul extern)
O infrastructură invizibilă este inutilă dacă este fragilă. În acest ultim capitol, închidem cercul siguranței. Vom implementa un sistem de monitorizare vizuală pentru a vedea „pulsul” clusterului în timp real și, cel mai important, un sistem de backup automatizat care să trimită datele noastre prețioase în afara serverului fizic (Offsite).
1. Pregătirea stocării și a regulilor de monitorizare
Ne conectăm pe nodul Worker (.112) și executăm crearea folderelor de bază pe stocarea replicată ZFS:
# Crearea folderelor pentru Monitorizare și Backup
sudo mkdir -p /mnt/data/monitoring/grafana
sudo mkdir -p /mnt/data/monitoring/prometheus
sudo mkdir -p /mnt/data/backups/duplicati/config
# Crearea manuală a fișierului de configurare Prometheus
sudo nano /mnt/data/monitoring/prometheus/prometheus.ymlÎn editorul nano, adăugați acest set de reguli de bază:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']Salvați (CTRL+X, Y, Enter) și aplicați permisiunile pentru ca Docker să poată scrie datele:
sudo chmod -R 777 /mnt/data/monitoring/
sudo chmod -R 777 /mnt/data/backups/2. Lansarea Stack-ului de Monitorizare (Grafana & Prometheus)
În Portainer, mergem la Stacks -> Add Stack și creăm un Stack nou numit monitoring:
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
volumes:
- /mnt/data/monitoring/prometheus:/prometheus
- /mnt/data/monitoring/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
grafana:
image: grafana/grafana:latest
volumes:
- /mnt/data/monitoring/grafana:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=parola_ta_secreta_grafana
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
networks:
swarm-public:
external: true3. Plasarea Plasei de Siguranță: Duplicati (Backup Offsite)
Creăm un alt Stack în Portainer numit backups:
version: '3.8'
version: '3.8'
services:
duplicati:
image: linuxserver/duplicati:latest
environment:
- PUID=1000
- PGID=1000
- TZ=Europe/Bucharest
# SETTINGS_ENCRYPTION_KEY este obligatorie pentru securizarea bazei de date interne
- SETTINGS_ENCRYPTION_KEY=Renuka2026Backup
# CLI_ARGS asigură accesul prin rețeaua Swarm și setează parola inițială
- CLI_ARGS=--webservice-interface=any --webservice-port=8200 --webservice-password=admin1234 --webservice-allowed-hostnames=*
volumes:
- /mnt/data/backups/duplicati/config:/config
- /mnt/data/wordpress:/source/wordpress
- /mnt/data/maintenance:/source/maintenance
networks:
- swarm-public
deploy:
placement:
constraints: [node.role == worker]
networks:
swarm-public:
external: trueMariaDB este o bază de date „vie”. Dacă Duplicati copiază folderul
db/ în timp ce baza scrie, backup-ul va fi corupt.Soluția (Dump Dinamic + Filtrare):- Pasul 1 (Cron Job): Rulează
crontab -epe Worker și adaugă linia pentru ora 02:50 AM:
50 02 * * * docker exec $(docker ps -q -f name=wordpress_db) mariadb-dump -u root -pParolaTaSecreta wordpress > /mnt/data/wordpress/database_backup.sql - Pasul 2 (Filtru Duplicati): În interfața Duplicati, la Filters, alege Exclude folder și selectează
source/wordpress/db/.
Astfel, salvăm doar fișierul .sql static, garantând o restaurare de succes!
4. Accesul prin Cloudflare Tunnel
Adăugăm rutele securizate în panoul Cloudflare Zero Trust pentru a accesa noile unelte:
- Dashboard Grafana:
stats.renuka.site➡️http://monitoring_grafana:3000 - Interfață Backup:
backup.renuka.site➡️http://backups_duplicati:8200
5. Scenariul de Coșmar: Disaster Recovery (Cum restaurăm?)
Dacă pierzi complet serverul fizic, ordinea operațiunilor este critică pentru a evita conflictele de scriere:
- Pasul 1 (Recuperarea): Instalezi Docker pe noul server, lansezi stack-ul
backupsși restaurezi datele în/mnt/data/wordpress. - Pasul 2 (Pornirea): Abia acum lansezi stack-ul
wordpressdin Portainer. - Pasul 3 (Injecția automată): Executăm scriptul “one-click” pe care îl pregătim pe Worker pentru a popula baza goală:
# Creăm scriptul de restaurare pe Worker
sudo nano /mnt/data/wordpress/restore_db.sh
# Adaugă acest cod (atenție la parola de root!):
#!/bin/bash
docker exec -i $(docker ps -q -f name=wordpress_db) mariadb -u root -pParolaTaSecreta wordpress < /mnt/data/wordpress/database_backup.sql
# Salvează și dă-i permisiuni de execuție:
sudo chmod +x /mnt/data/wordpress/restore_db.shRulează sudo /mnt/data/wordpress/restore_db.sh și site-ul reînvie instantaneu, identic cu momentul ultimului backup.
Ai reușit! Ai parcurs un drum tehnic complex, făcând saltul de la un hosting clasic la o arhitectură Enterprise distribuită. Infrastructura ta este acum un ecosistem matur, agil și complet invizibil pentru atacatori.
Stay Free! Stay Hidden! Stay Indestructible!